
Manuel Simoni's blog about programming (languages).
Saturday, November 24, 2012
Monday, November 19, 2012

Thursday, November 15, 2012

Wednesday, November 14, 2012

Friday, November 9, 2012


Thursday, November 8, 2012



Monday, November 5, 2012

Sunday, November 4, 2012

Thursday, September 27, 2012

Wednesday, September 19, 2012

Saturday, September 8, 2012
Having both fexprs and macros
Lexically-scoped fexprs and first-class environments make it simple to do hygienic metaprogramming, using less machinery than hygienic macro systems, and they also require less concepts in the language: there is no need to specify a preprocessing phase.
The downside is that fexprs always incur an interpretative overhead with current technology. Many are convinced that those fexprs that do similar things to what macros do can be partially evaluated: "my research in static analysis leads me to believe that we will be able to erase that overhead for the common case--where first-class macros are used to do the job of compile-time macros" writes Matt Might, for example.
In my new language, Wat, I've implemented both fexprs and macros. Macros are expanded at runtime, when they are first encountered, and their result is memoized in the syntax tree, a technique described in two interesting articles (1, 2) related to the SCM Scheme implementation.
In Wat, MACRO is a special form that can be wrapped around a combiner, and causes calls to that combiner to be memoized in the source tree. An example, LET:
Macros complicate the language quite a bit; but used in moderation, especially for forms like LET that are basically never changed nor used in a higher-order fashion, they should be unproblematic, and offer a nice speed boost. Fexprs should be used for more complex tasks that require special attention to hygiene, or need to do things that macros can't do, whereas macros could be used for simple transformation and processing tasks, such as UNTIL, above.
Oh, and it should also be noted that these macros enjoy a nice level of hygiene already, by virtue of first-class environments and first-class combiners. For example, UNTIL above doesn't insert the symbols WHILE or NOT into the generated code - it inserts the actual values, therefore being protected from variable shadowing by calling code.
The downside is that fexprs always incur an interpretative overhead with current technology. Many are convinced that those fexprs that do similar things to what macros do can be partially evaluated: "my research in static analysis leads me to believe that we will be able to erase that overhead for the common case--where first-class macros are used to do the job of compile-time macros" writes Matt Might, for example.
In my new language, Wat, I've implemented both fexprs and macros. Macros are expanded at runtime, when they are first encountered, and their result is memoized in the syntax tree, a technique described in two interesting articles (1, 2) related to the SCM Scheme implementation.
In Wat, MACRO is a special form that can be wrapped around a combiner, and causes calls to that combiner to be memoized in the source tree. An example, LET:
(def let
(macro (vau (bindings . body) #ign
(cons (list* lambda (map car bindings) body)
(map cadr bindings)))))
With a bit of sugar, one can write macros that look almost like in Common Lisp:
(define-macro (until test . body) (list* while (list not test) body))
Macros complicate the language quite a bit; but used in moderation, especially for forms like LET that are basically never changed nor used in a higher-order fashion, they should be unproblematic, and offer a nice speed boost. Fexprs should be used for more complex tasks that require special attention to hygiene, or need to do things that macros can't do, whereas macros could be used for simple transformation and processing tasks, such as UNTIL, above.
Oh, and it should also be noted that these macros enjoy a nice level of hygiene already, by virtue of first-class environments and first-class combiners. For example, UNTIL above doesn't insert the symbols WHILE or NOT into the generated code - it inserts the actual values, therefore being protected from variable shadowing by calling code.
Thursday, September 6, 2012
Mixing first-order and higher-order control
It's desirable for a language to support exceptions (preferably restartable ones), unwind protection, dynamic binding, and delimited continuations. [Adding Delimited and Composable Control to a Production Programming Environment, Delimited Dynamic Binding]
I've found a tractable way to implement these features in the language I'm currently working on, Wat.
My approach is to totally separate first-order control from higher-order control.
There is a set of Common Lisp-like first-order forms:
Restartable exceptions are implemented in terms of these first-order forms and dynamically-bound variables, which are also provided natively.
In addition there's a completely separate set of higher-order control forms from A Monadic Framework for Delimited Continuations.
Delimited continuations are implemented using a technique similar to Exceptional Continuations: ordinary code paths run on the normal JS stack; when a continuation is captured, the stack is unwound frame by frame up to the prompt, and at each frame, a resumption is added to the continuation that is built up during the unwinding. This technique is ten times faster than a naive scheme with heap-allocated stack frames, but currently doesn't support TCO.
First-order control is used for quotidian control flow, whereas higher-order control is used for heavy control flow lifting, such as making a REPL written in direct style work in the browser's asynchronous environment.
This is a quite intuitive model: in the small, one has the usual Common Lisp control flow, including restartable exceptions, whereas in the large, behind the scenes, control flow may be arbitrarily abstracted and composed with the higher-order control forms.
I've found a tractable way to implement these features in the language I'm currently working on, Wat.
My approach is to totally separate first-order control from higher-order control.
There is a set of Common Lisp-like first-order forms:
- block and return-from that establish and invoke a lexically-scoped one-shot escape continuation, respectively.
- unwind-protect aka "finally". Notably, unwind-protect is only sensitive to return-from, not to aborts via higher-order control.
These forms are implemented natively using JS try/catch and finally.
In addition there's a completely separate set of higher-order control forms from A Monadic Framework for Delimited Continuations.
Delimited continuations are implemented using a technique similar to Exceptional Continuations: ordinary code paths run on the normal JS stack; when a continuation is captured, the stack is unwound frame by frame up to the prompt, and at each frame, a resumption is added to the continuation that is built up during the unwinding. This technique is ten times faster than a naive scheme with heap-allocated stack frames, but currently doesn't support TCO.
First-order control is used for quotidian control flow, whereas higher-order control is used for heavy control flow lifting, such as making a REPL written in direct style work in the browser's asynchronous environment.
This is a quite intuitive model: in the small, one has the usual Common Lisp control flow, including restartable exceptions, whereas in the large, behind the scenes, control flow may be arbitrarily abstracted and composed with the higher-order control forms.
Wednesday, September 5, 2012
Reactive Demand Programming
David Barbour has created a very promising and exciting paradigm for writing interactive, networked applications: Reactive Demand Programming (RDP).
RDP is very sophisticated and I can't really do it justice here, but its salient points are:
RDP is very sophisticated and I can't really do it justice here, but its salient points are:
- An RDP application is a dynamically-changing set of semi-permanent, bidirectional data exchanges, called behaviors. What pipes are to Unix, behaviors are to RDP.
- A signal is a monodirectional channel carrying a value, and varies discretely over time.
- A behavior is made up of one or more input signals, called demands, and a single output signal.
- RDP builds in the notion of anticipation - every signal update comes with the expected duration the new value is valid. This allows low latency through smart scheduling.
- [Update: See David's corrections in the comments.]
An example for a behavior would be a camera receiving move and zoom commands (or rather demands) with discrete time intervals (e.g. as long as a user moves the camera joystick) from one or more users on input signals, interpolating these commands using some deterministic decision procedure (such as averaging all commands), and outputting camera frames on the output signal, with the anticipation measure telling clients something about the rate at which the camera refreshes, allowing them to smartly perform display reprocessing.
The best way to get started is the README of David's RDP implementation. David has also just posted a progress report on his blog, which contains many articles on RDP.
I think RDP is one of the most exciting developments in interactive application development and is worth checking out.
Thursday, August 23, 2012

Tuesday, August 14, 2012
Switching between TCO and non-TCO at runtime
Here's a fun idea, that should work in a language with fexprs, or an incremental/reactive macro expander. It relies on the property that EVAL evaluates the form in tail position. Tail-call optimization could be switched off and on during debugging for more useful stack traces, and even arbitrarily at runtime. The loss of useful stacktraces is not a non-issue, as witnessed by attempts at more useful stack traces in MIT Scheme and in SISC.
How it works: all expressions in tail position (e.g. the last expression of a BEGIN, the last expression in a lambda, the branches of an IF, ...) are automatically (by the parser or something) wrapped in a call to the operator TCOIFY:
(lambda () (foo) (bar)) becomes
(lambda () (foo) (tcoify (bar)))
(if (quux) (do-something) (do-something-else)) becomes
(if (quux) (tcoify (do-something)) (tcoify (do-something-else)))
etc.
Ordinarily, TCOIFY would be a fexpr that directly evaluates its argument, in tail position:
(def tcoify (vau (x) env (eval x env)))
When TCOIFY is defined thusly, (tcoify expr) is equal to expr for the purposes of TCO, because EVAL evaluates X in tail position.
For useful stack traces, one would define TCOIFY as a function. Argument evaluation needs to happen before application, so TCOIFY would prevent TCO:
(def tcoify (lambda (x) x))
By switching between the two definitions of TCOIFY at runtime, tail-call optimization can be turned on and off.
How it works: all expressions in tail position (e.g. the last expression of a BEGIN, the last expression in a lambda, the branches of an IF, ...) are automatically (by the parser or something) wrapped in a call to the operator TCOIFY:
(lambda () (foo) (bar)) becomes
(lambda () (foo) (tcoify (bar)))
(if (quux) (do-something) (do-something-else)) becomes
(if (quux) (tcoify (do-something)) (tcoify (do-something-else)))
etc.
Ordinarily, TCOIFY would be a fexpr that directly evaluates its argument, in tail position:
(def tcoify (vau (x) env (eval x env)))
When TCOIFY is defined thusly, (tcoify expr) is equal to expr for the purposes of TCO, because EVAL evaluates X in tail position.
For useful stack traces, one would define TCOIFY as a function. Argument evaluation needs to happen before application, so TCOIFY would prevent TCO:
(def tcoify (lambda (x) x))
By switching between the two definitions of TCOIFY at runtime, tail-call optimization can be turned on and off.
Saturday, August 11, 2012
Delimited continuations do dynamic-wind
Oleg's argument against call/cc links to one of his lesser known posts, Delimited continuations do dynamic-wind. In it he first shows how to implement yielding generators in terms of delimited control, and then shows how such generators lead to a natural definition of dynamic-wind, in userland, whereas with undelimited continuations, dynamic-wind has to be primitive.
(This is not entirely true. Kernel can implement dynamic-wind in userland, too, by means of its guarded undelimited continuations. And in Scheme 48, dynamic-wind is also implemented in userland with undelimited continuations, albeit in terms of a slightly lower level API than call/cc. Same is true for other Schemes, such as MIT Scheme. And probably the earliest definition of dynamic-wind, in Embedding Continuations in Procedural Objects is also in userland, so I'm a bit confused actually, as to why Oleg considers dynamic-wind primitive...)
Back to Oleg's generators in terms of delimited control. While one may argue against first-class continuations, whether delimited or not, I think having them in the language is great for quickly prototyping different ideas, such as generators. This has always been a forte of Lisp, and so high-powered control flow operations seem a good fit for the language, even if their runtime cost may be slightly higher than a more specialized, native implementation of some specific control feature, such as generators.
The basic ideas of generators are: you have a block of code, the generator, which may either normally return a value by means of reaching the end of the block, or it may intermittently yield a value. To call a generator, we need a boundary around it, so we wrap it in a prompt with reset. Yielding suspends the generator, capturing its delimited continuation up to the prompt, and delivers the value and this continuation to the caller, outside the boundary. Value and continuation are wrapped up in a special record type, so the caller can distinguish yields from an ordinary return, which doesn't wrap the value in any way (and neither provides a continuation for resuming, obviously). (This could probably be handled more elegantly with Racket's abort handlers.)
In this Gist, I've commented Oleg's implementation of generators and dynamic-wind.
I think it's a great example of how simple it is to add specific control flow features to a language with general (delimited) continuations.
Oh, and in typical Oleg style, the article then goes on about how you can implement call/cc in terms of generators, which makes his dynamic-wind compatible with existing Scheme examples using call/cc.
(This is not entirely true. Kernel can implement dynamic-wind in userland, too, by means of its guarded undelimited continuations. And in Scheme 48, dynamic-wind is also implemented in userland with undelimited continuations, albeit in terms of a slightly lower level API than call/cc. Same is true for other Schemes, such as MIT Scheme. And probably the earliest definition of dynamic-wind, in Embedding Continuations in Procedural Objects is also in userland, so I'm a bit confused actually, as to why Oleg considers dynamic-wind primitive...)
Back to Oleg's generators in terms of delimited control. While one may argue against first-class continuations, whether delimited or not, I think having them in the language is great for quickly prototyping different ideas, such as generators. This has always been a forte of Lisp, and so high-powered control flow operations seem a good fit for the language, even if their runtime cost may be slightly higher than a more specialized, native implementation of some specific control feature, such as generators.
The basic ideas of generators are: you have a block of code, the generator, which may either normally return a value by means of reaching the end of the block, or it may intermittently yield a value. To call a generator, we need a boundary around it, so we wrap it in a prompt with reset. Yielding suspends the generator, capturing its delimited continuation up to the prompt, and delivers the value and this continuation to the caller, outside the boundary. Value and continuation are wrapped up in a special record type, so the caller can distinguish yields from an ordinary return, which doesn't wrap the value in any way (and neither provides a continuation for resuming, obviously). (This could probably be handled more elegantly with Racket's abort handlers.)
In this Gist, I've commented Oleg's implementation of generators and dynamic-wind.
I think it's a great example of how simple it is to add specific control flow features to a language with general (delimited) continuations.
Oh, and in typical Oleg style, the article then goes on about how you can implement call/cc in terms of generators, which makes his dynamic-wind compatible with existing Scheme examples using call/cc.
Tuesday, August 7, 2012
Scheme's missing ingredient: first-class type tags
I've always felt that Scheme does data and types wrong, but I couldn't really say what bothered me until yesterday. After all, R7RS now has define-record-type for creating disjoint types. But that ain't enuff!
In my new language, Wat, I've found a satisfying solution, inspired by Kernel's encapsulation types, but going beyond them slightly. There are two procedures:
In my new language, Wat, I've found a satisfying solution, inspired by Kernel's encapsulation types, but going beyond them slightly. There are two procedures:
- (make-type) returns a list of three elements: 1) a first-class type 2) a tagger function for tagging a value with that type, creating a tagged object and 3) an untagger function for extracting the value of tagged objects of that type.
- (type-of obj) returns the first-class type of an object. The crucial point is that type-of not only works for tagged objects of user-defined types created by make-type, but also for all built-in types. E.g. (type-of 12) will return the number first-class type.
This system has the benefits of Kernel's encapsulated types: only someone with access to the tagger function (capability) may create new instances of a type. Only someone with access to the untagger function may access the contents of tagged objects. So object contents are potentially fully encapsulated.
But at the same time, the fact that every object, including built-in ones, has a first-class type makes it possible to efficiently program generically. E.g. one may create Smalltalk-like dynamic dispatch by using the first-class types of objects as indexes into a virtual lookup table of a generic function. This is not possible in either Scheme or Kernel. In both languages, programming generically requires one to use a cascade of type predicates (e.g. number?).
Example in Wat:
Example in Wat:
; destructuringly bind the three elements ; returned by make-type (def (person-type person-tagger person-untagger) (make-type)) (define (make-person name email) (person-tagger (list name email))) ; untagger also performs a type check that ; person is in fact of type person (define (get-name person) (car (person-untagger person))) (define (get-email person) (cadr (person-untagger person))) (define p1 (make-person "Quux" "quux@example.com")) (get-name p1) --> "Quux" (get-email p1) --> "quux@example.com"
Thursday, August 2, 2012

Wednesday, August 1, 2012
Understanding metacontinuations for delimited control
Metacontinuations arise in some implementations of delimited control such as in A Monadic Framework for Delimited Continuations.
In addition to the usual continuation register K, an interpreter with metacontinuations has a metacontinuation register MK.
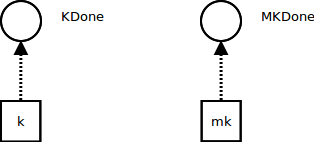
Initially, K points to an empty continuation KDone, and MK points to an empty metacontinuation MKDone:
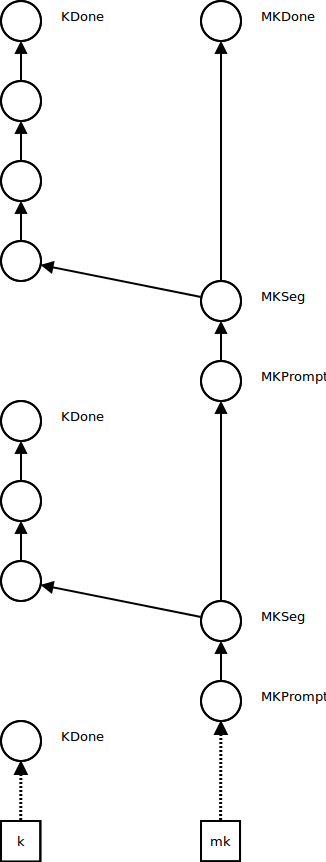
When the ordinary continuation reaches KDone, we look at the metacontinuation: if it's MKDone, the program is finished and we return its result. Otherwise, we underflow the metacontinuation by reestablishing the next continuation segment as the current continuation and the next metacontinuation as the current metacontinuation.
In addition to the usual continuation register K, an interpreter with metacontinuations has a metacontinuation register MK.
Initially, K points to an empty continuation KDone, and MK points to an empty metacontinuation MKDone:
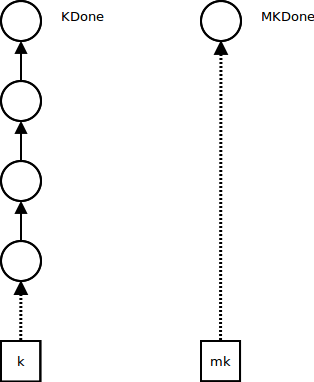
Ordinary computations influence only the continuation K - they push continuation frames while the metacontinuation MK stays the same:
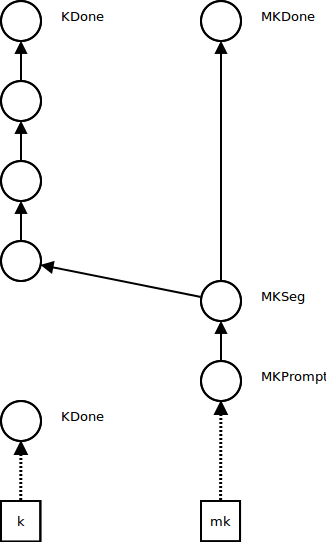
Control operations such as pushing a prompt (continuation delimiter) influence the metacontinuation. A segment metacontinuation frame MKSeg stores the continuation segment at which the control effect occurred and a pointer to the next metacontinuation. A prompt metacontinuation frame MKPrompt remembers the prompt and points to the segment frame (the reason for splitting this operation into two metacontinuation frames is that it makes the code simpler; see the paper). MK now points to the prompt metaframe, and K points to a new empty continuation KDone:
Further non-control computations occur in the new continuation, while the metacontinuation stays the same, as before:
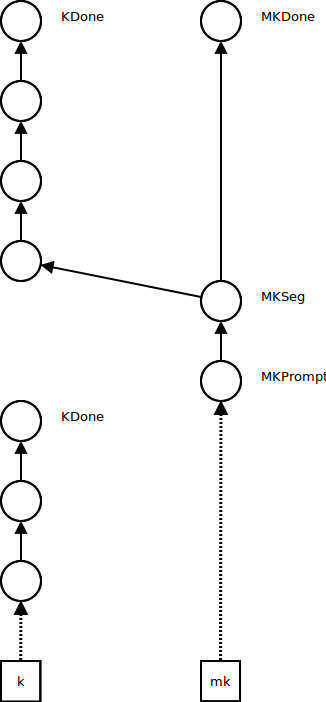
Further control operations push frames onto the metacontinuation, and create new empty continuations, as before:
When the ordinary continuation reaches KDone, we look at the metacontinuation: if it's MKDone, the program is finished and we return its result. Otherwise, we underflow the metacontinuation by reestablishing the next continuation segment as the current continuation and the next metacontinuation as the current metacontinuation.
An alternative API for continuations
Call/cc is the most well-known API for exposing first-class continuations to userland. But there is another API that's used in Scheme 48 and is also described in a paper by Feeley.
(continuation-capture f) --- calls f with the current continuation as argument. In contrast to call/cc, the continuation is not a procedure, but an opaque first-class object. (In Scheme 48, this is called primitive-cwcc.)
(continuation-graft k thunk) --- calls thunk in the continuation k. In contrast to call/cc, k doesn't receive a value computed in another continuation, but rather thunk's effect is performed in k. (Scheme 48: with-continuation.)
The implementation difference to call/cc is minimal, and expressing call/cc in terms of this API is simple:
I can't exactly put my finger on it, but this API seems more powerful than call/cc. In the implementation of delimited dynamic binding in terms of continuation marks I'm working on, there is a need for fetching the marks of another continuation. With call/cc this is impossible, but with this API I can prepend a thunk to the continuation in question, then in this thunk fetch the continuation's marks, and then jump out of it again.
(continuation-capture f) --- calls f with the current continuation as argument. In contrast to call/cc, the continuation is not a procedure, but an opaque first-class object. (In Scheme 48, this is called primitive-cwcc.)
(continuation-graft k thunk) --- calls thunk in the continuation k. In contrast to call/cc, k doesn't receive a value computed in another continuation, but rather thunk's effect is performed in k. (Scheme 48: with-continuation.)
The implementation difference to call/cc is minimal, and expressing call/cc in terms of this API is simple:
(define (call/cc f)
(continuation-capture
(lambda (k)
(f (lambda (val)
(continuation-graft k (lambda () val)))))))
I can't exactly put my finger on it, but this API seems more powerful than call/cc. In the implementation of delimited dynamic binding in terms of continuation marks I'm working on, there is a need for fetching the marks of another continuation. With call/cc this is impossible, but with this API I can prepend a thunk to the continuation in question, then in this thunk fetch the continuation's marks, and then jump out of it again.
Continuation marks
Continuation marks are a mechanism for attaching key-value data to continuation frames. There are two primitives:
(call/cm key value thunk) --- calls thunk with a new continuation mark binding key to value. If the current innermost continuation frame already has a mark with that key, it is overwritten.
(current-marks key) --- returns the list of values of current marks with the given key, from innermost to outermost continuation frame.
Example:
(call/cm 'foo 12 (lambda () (current-marks 'foo))) ---> (12)
So, continuation marks are an obvious mechanism for implementing dynamic binding. That duplicate marks on the same frame overwrite each other makes them play nice with TCO.
I've implemented CMs in the Kernel implementation I'm currently playing with. Every continuation frame has a marks dictionary mapping keys to values. Current-marks walks the continuation chain in the obvious way, collecting matching marks into a list. Call/cm clones the current continuation frame (including the marks dictionary) and updates the binding for the given key. I'm not entirely sure if that's the correct way to implement CMs, but it seems so.
I'm currently trying to implement delimited dynamic binding on top of continuation marks (using the metacontinuation approach from A Monadic Framework), but this seems slightly above my pay grade.
(call/cm key value thunk) --- calls thunk with a new continuation mark binding key to value. If the current innermost continuation frame already has a mark with that key, it is overwritten.
(current-marks key) --- returns the list of values of current marks with the given key, from innermost to outermost continuation frame.
Example:
(call/cm 'foo 12 (lambda () (current-marks 'foo))) ---> (12)
So, continuation marks are an obvious mechanism for implementing dynamic binding. That duplicate marks on the same frame overwrite each other makes them play nice with TCO.
I've implemented CMs in the Kernel implementation I'm currently playing with. Every continuation frame has a marks dictionary mapping keys to values. Current-marks walks the continuation chain in the obvious way, collecting matching marks into a list. Call/cm clones the current continuation frame (including the marks dictionary) and updates the binding for the given key. I'm not entirely sure if that's the correct way to implement CMs, but it seems so.
I'm currently trying to implement delimited dynamic binding on top of continuation marks (using the metacontinuation approach from A Monadic Framework), but this seems slightly above my pay grade.
Thursday, July 26, 2012

Tuesday, July 24, 2012


Friday, July 20, 2012



Thursday, July 19, 2012

Wednesday, July 18, 2012

Thursday, July 12, 2012




Wednesday, July 11, 2012


Tuesday, July 10, 2012

Sunday, July 8, 2012


Saturday, July 7, 2012

Friday, July 6, 2012


Thursday, July 5, 2012



Thursday, June 28, 2012
What I've been reading

If you want to impress your coworkers with terms like cobordism: Physics, Topology, Logic and Computation: A Rosetta Stone:
A simple diagram ... can now be seen as a quantum process, a tangle, a computation — or an abstract morphism in any braided monoidal category! This is just the sort of thing one would hope for in a general science of systems and processes.An Applicative Control-Flow Graph Based on Huet’s Zipper. Somebody actually used FP in the real world -- well, to write a compiler -- and can report that it did indeed in fact work. Related, here's my favorite zipper tutorial.
Resumable exceptions can macro-express delimited dynamic variables. Because you can never test your intuition enough.
More links: Ian Piumarta's liboop; Eric Torreborre on total FP; VeriML; automatic scoping and destructor functionality in C.
HT Paul Snively, Daniel Yokomizo, Patrick Thomson.
Tuesday, June 26, 2012
PoshLusT
PLT is a resentful business - there are so many accolades for blowhards, it can be hard to stomach.
Thankfully, the writer Vladimir Nabokov offers a remedy: the word poshlust:
Thankfully, the writer Vladimir Nabokov offers a remedy: the word poshlust:
Let me refer to one more method of dealing with literature- and this is the simplest and perhaps most important one. If you hate a book, you may still derive artistic delight from imagining other and better ways of looking at things, or, what is the same, expressing things, than the author you hate does.The mediocre, the false, the poshlust-remember that word-can at least afford a mischievous but very healthy pleasure, as you stamp and groan through a second-rate book which has been awarded a prize.He also has advice for dealing with the good stuff:
But the books you like must be read with shudders and gasps. Let me submit the following practical suggestion. Literature, real literature, must not be gulped like some potion which may be good for the heart or good for the brain-the brain, that stomach of the soul. Literature must be taken and broken to bits, pulled apart, squashed-then its lovely reek will be smelt in the hollow of the palm, it will be munched and rolled upon the tongue with relish; then, only then, its rare flavour will be appreciated at its true worth and the broken and crushed parts will again come together in your mind and disclose the beauty of a unity to which you have contributed something of your own blood.What PLT made you shudder and gasp? For me, the first things that come to mind are Kernel, the MOP, Ωmega, and A monadic framework for delimited continuations.
Friday, May 18, 2012
[Meta] Comments widget
I've added a recent comments widget to the sidebar of the blog.
There have been many excellent comments recently, and AoE completists may want to check them out.
[Unfortunately, the links don't take you to the comments themselves but rather to the page. Investigating.]
There have been many excellent comments recently, and AoE completists may want to check them out.
[Unfortunately, the links don't take you to the comments themselves but rather to the page. Investigating.]
Manuel, have you lost interest in Kernel?
... I was asked yesterday two times on #interactiveprogramming.
No, absolutely not!
I simply got stopped in the tracks trying to find a satisfactory way of adding named arguments to it. I need that feature to consider it complete.
However, two new old topics will probably be raging in my skull in the future:
No, absolutely not!
I simply got stopped in the tracks trying to find a satisfactory way of adding named arguments to it. I need that feature to consider it complete.
However, two new old topics will probably be raging in my skull in the future:
- Static types, because defining red-black trees that are balanced by construction makes so much sense (and it may finally help me understand those pesky trees).
- Interactive execution, because Roly Perera.
Thursday, May 17, 2012
#interactiveprogramming IRC
For the discussion of interactive programming languages, I'm now hanging out on #interactiveprogramming on chat.freenode.net IRC.
You're all happily invited to join!
You're all happily invited to join!
Tuesday, May 15, 2012
Back to the future
Roly Perera, who's doing awesome work on interactive programming is apparently taking up blogging again. Yay!
Back to the future
I know not of these “end users” of whom you speak. There is only programming. – Unknown programmer of the futureJonathan Edwards recently wrote that an IDE is not enough. To break out of our current commitment to text files and text editors requires a new programming paradigm, not just a fancy IDE. I feel the same. I’ve spent the last two and a half years moving my interactive programming work forward, and I feel I’m now ready to start sharing. Bret Victor blew us away with his influential, Jonathan-Edwards-inspired, mindmelt of a demo but was conspicuously quiet on how to make that kind of stuff work. (Running and re-running fragments of imperative code that spit out effects against a shared state, for example, does not a paradigm make, even if it can be made to work most of the time. “Most of time” is not good enough.) I won’t be blowing anyone’s minds with fancy demos, unfortunately, but over the next few months I’ll be saying something about how we can make some of this stuff work. I’ve been testing out the ideas with a proof-of-concept system called LambdaCalc, implemented in Haskell.
Friday, April 27, 2012
Physical code
Roly Perera, who is doing awesome work on continuously executing programs and interactive programming, tweeted that we should take inspiration from nature for the next generation of PLs:
- Lesson #1: it's physical objects all the way down. #
- Lesson #2: there is only one "from-scratch run", and we're living in it. #
- Lesson #3: there are no black boxes. #
The first point is one I'm thinking about in the context of what I call hypercode.
Common Lisp is - as usual - an interesting example: with its Sharpsign Dot macro character, one can splice in real objects into the source code loaded from a file.
E.g. if you put the text (* #.(+ 1 2) 3) into a file, the actual code when the file is loaded is (* 3 3).
And with Sharpsign Equal-Sign and Sharpsign Sharpsign, we can construct cyclic structures in files: '#1=(foo . #1#) reads as a pair that contains the symbol foo as car, and itself as cdr: #1=(FOO . #1#) (don't forget to set *print-circle* to true if you don't want to get a stack overflow in the printer).
The question I'm thinking about is: what happens if source code consists of the syntax objects themselves, and not their representations in some format? Is it just more of the same, or a fundamental change?
For example: what if you have a language with first-class patterns and you can now manipulate these patterns directly - i.e. they present their own user interface? Is this a fundamental change compared to text or not?
As Harrison Ainsworth tweeted:
For example: what if you have a language with first-class patterns and you can now manipulate these patterns directly - i.e. they present their own user interface? Is this a fundamental change compared to text or not?
As Harrison Ainsworth tweeted:
- Is parsing not an illusory problem caused by using the wrong data structure? #
Wednesday, April 18, 2012
The Supposed Primacy of Text

As should be obvious to my regular readers, I'm using the Axis of Eval to post raw thoughts. I don't do the work of rigorously thinking these thoughts through. I'm trying to narrate my mental work, in whatever state it is at the moment, with the hope to engage in dialogue with those of you with similar interests.
With this disclaimer out of the way, another take on the text/graphical axis.
In a comment on The Escape from the Tyranny of the Typewriter, John writes:
Okay, I'll play devil's advocate here. Text is the most articulate form of expression we have; it's so potent that even your graphical representation actually resorts to it. If you're going to introduce something else as well, that reduces simplicity, so there should be a very clear reason for it, and what you introduce should be in some sense manifestly The Right Thing.But the plain text we use with computers is hugely impoverished, compared to pre-computer texts. Compare to Dadaists' use of text (the art at beginning of text) or religious texts, which were widely "scribbled in the margins", and adorned with many graphical features.

Or take mathematical text: it has rich, mostly informal structure for conveying information:

This brings us to computers' favorite: a sequence of code-points. That is simply in no way adequate to represent the exploits of the past, not to speak of the future.
Modern mathematicians are shoehorned into writing their fomulas in LaTex and having them presented to them in ASCII art in their mathematical REPLs.
So let's turn the tables: Plain text is a particular special case of using a general purpose graphical display to display sequences of code points. Furthermore, plain text stored in a file is also just a special case of arbitrary information stored in a file.
Sunday, April 15, 2012
Escape from the Tyranny of the Typewriter

One misconception of computing is that plain text is somehow the natural thing for a computer to process. False. It only appears that way, because even the lowest layers of our computing infrastructure are already toolstrapped to work with the bit patterns representing plain text.
Thinking about graphical syntax, combined with the brain stimulating powers of Kernel, it occurred to me that in a fundamental sense,
(+ 1 2) is really just a shorthand for (eval (list + 1 2) (get-current-environment))(Note that I'm assuming the existence of a Sufficiently Smart Partial Evaluator in all my investigations. As history shows, after the 5 decades it takes for Lisp ideas to become mainstream, it's perfectly possible to implement them efficiently.)
This harks back to my previous post about using and mentioning syntax. The (+ 1 2) is the way we directly use the syntax, whereas (eval (list + 1 2) (get-current-environment)) is the way we use mentioned syntax.
But why have two? Obviously, in a typewriter-based syntax, writing (eval (list + 1 2) (get-current-environment)) all the time would be much too cumbersome. But in a graphical syntax, the difference between the two might be just a different border color for the corresponding widgets.
This means: maybe we don't even need a way to use syntax, and can get by with just a way of mentioning it.
Put differently: In typewriter-based syntax, we cannot afford to work with mentioned syntax all the time, because we would need to wrap it in (eval ... (get-current-environment)) to actually use it. A graphical syntax would make it possible to work solely with mentioned syntax, and indicate use in a far more lightweight way (e.g. a different color).
But maybe that's bull.
What is Lisp syntax, really, and the use-mention distinction
In a recent comment, John Shutt wrote:
I think the cornerstone of Lisp, wrt to syntax, is that the barrier between using a piece of syntax and mentioning it is very low.
When I write (+ 1 2), I use the syntax to compute 3. But when I write '(+ 1 2) I just mention it. Note that the difference between use and mention is just one small sign, the quote '.
Let's take a piece of syntax -- corresponding to (let ((x 1) (y 2)) (+ x y)) -- in a hypothetical graphical syntax:
I do agree that the success of Lisp depends quite heavily on the fact that it has no syntax dedicated to semantics. But this means that, to the extent that a language introduces syntax dedicated to semantics, to just that extent the language becomes less Lisp.After a couple of days of thinking about this on and off, in the context of hypercode/graphical syntax, I came to these thoughts:
I think the cornerstone of Lisp, wrt to syntax, is that the barrier between using a piece of syntax and mentioning it is very low.
When I write (+ 1 2), I use the syntax to compute 3. But when I write '(+ 1 2) I just mention it. Note that the difference between use and mention is just one small sign, the quote '.
Let's take a piece of syntax -- corresponding to (let ((x 1) (y 2)) (+ x y)) -- in a hypothetical graphical syntax:
| let |
|
||||
| + x y |
The green border around the variable bindings, and their gray background is meant to indicate that the set of bindings is not just usual Lisp list-based syntax, but rather that we're using a special widget here, that affords convenient manipulation of name-value mappings.
This point is important. The graphical syntax is not equivalent to (let ((x 1) (y 2)) (+ x y)) -- it doesn't use lists to represent the LET's bindings, but rather a custom widget. The LET itself and the call to + do use "lists", or rather, their graphical analogue, the gray bordered boxes.
So it seems that we have introduced syntax dedicated to semantics, making this language less Lisp, if John's statement is true.
But I believe this is the wrong way to look at it. Shouldn't we rather ask: does this new syntax have the same low barrier between using and mentioning it, as does the existing Lisp syntax?
Which leads to the question: how can we add new (possibly graphical) syntax to Lisp, while keeping the barrier between use and mention low?
In conclusion: my hunch is that we can add syntax to Lisp, without making it less Lisp, as long as the new syntax can be mentioned as naturally as it can be used.
Follow-up: Escape from the Tyranny of the Typewriter.
HN discussion
This point is important. The graphical syntax is not equivalent to (let ((x 1) (y 2)) (+ x y)) -- it doesn't use lists to represent the LET's bindings, but rather a custom widget. The LET itself and the call to + do use "lists", or rather, their graphical analogue, the gray bordered boxes.
So it seems that we have introduced syntax dedicated to semantics, making this language less Lisp, if John's statement is true.
But I believe this is the wrong way to look at it. Shouldn't we rather ask: does this new syntax have the same low barrier between using and mentioning it, as does the existing Lisp syntax?
Which leads to the question: how can we add new (possibly graphical) syntax to Lisp, while keeping the barrier between use and mention low?
In conclusion: my hunch is that we can add syntax to Lisp, without making it less Lisp, as long as the new syntax can be mentioned as naturally as it can be used.
Follow-up: Escape from the Tyranny of the Typewriter.
HN discussion
[Meta] possibly lost comment
If you've posted a comment in the past couple days, and it hasn't showed up, please repost it. Thanks.
(The Blogger GUI showed me that there's an unmoderated comment, but when I clicked on it, it wasn't there, so maybe it got lost somehow.)
(The Blogger GUI showed me that there's an unmoderated comment, but when I clicked on it, it wasn't there, so maybe it got lost somehow.)
Thursday, April 5, 2012
Fear and Loathing at the Lisp Syntax-Semantics Interface

You poor fool! Wait till you see those goddamn parentheses.
Recent investigations of xonses and first-class patterns have driven home an important point:
Part of Lisp's success stems from its heavy use of puns.
Take (LET ((X 1) (Y 2)) (+ X Y)) for example. The pun here is that the same syntactic device - parentheses - is used to express two wildly different things: calls to the LET and + combiners on the one hand, and a list of bindings on the other.

Let's step back from Lisp's typewriter-based syntax for a moment, and imagine a graphical 2D syntax and a convenient 2Dmacs hypercode editor. Since we're now fully graphic, fully visual, it makes little sense to construct lists. We construct real widgets. So we would have one widget for "list of bindings" and all kinds of snazzy displays and keyboard shortcuts for working with that particular kind of form.
We don't have that editor yet, but still it makes sense to think about first-class forms. Right now, we restrict ourselves to lists and atoms. But why shouldn't the list of bindings of a LET be a special form, with a special API? E.g. we could write (LET [bindings [binding X 1] [binding Y 2]] (+ X Y)). Of course this is horrible. But look back at the imaginary 2D editor again. There we wouldn't have to write the [bindings [binding ... stuff. We would be manipulating a first-class form, a special GUI widget for manipulating a list of bindings...
Monday, April 2, 2012
Xonses progress report
I have rewritten my interpreter to use xonses throughout. As expected, Lisp code that doesn't use them is unaffected, and continues running as-is.
To recap: xonses are like conses, but in addition to car and cdr, they may have any number of other slots.
() == {} ;; nil is just an empty xons
(a) == { :car a :cdr {} }
(:foo 1) == { :foo 1 }
(:foo 1 2 3) == { :foo 1 :car 2 :cdr { :car 3 :cdr {} } }
(open-file "README" :mode "rw" :create-if-not-exists #t) ==
{ :mode "rw" :create-if-not-exists #t :car "open-file" :cdr { :car "README" :cdr {} } }
The differences between a Lisp/Kernel with conses and one with xonses are mostly:
To recap: xonses are like conses, but in addition to car and cdr, they may have any number of other slots.
() == {} ;; nil is just an empty xons
(a) == { :car a :cdr {} }
(:foo 1) == { :foo 1 }
(:foo 1 2 3) == { :foo 1 :car 2 :cdr { :car 3 :cdr {} } }
(open-file "README" :mode "rw" :create-if-not-exists #t) ==
{ :mode "rw" :create-if-not-exists #t :car "open-file" :cdr { :car "README" :cdr {} } }
The differences between a Lisp/Kernel with conses and one with xonses are mostly:
- There is no longer a separate nil. A xons without car and cdr is treated as nil, even if it has other slots.
- The usual pair? predicate changes from (instance? obj Pair) to (and? (instance? obj Pair) (not? (null? obj)).(These previous two rules have to do with the fact that xonses are more expressive than conses, and so we lose some "sharpness".)
- Pattern matching is extended, so that not only car and cdr are matched recursively, but all slots.
- Evaluation of arguments is extended: like in Kernel, an applicative cdrs down its operands and evaluates each, building the arguments list. In addition we now also evaluate the other slots of the first xons (Open question: should we also evaluate the other slots of later xonses? Probably yes).
All in all, xonses fit into the usual Lisp framework.
One big problem remains, which is why my new interpreter doesn't work:
In the x-expression (open-file "README" :mode "rw"), the :mode slot gets attached to the first xons, the one whose car is open-file. Per the usual evaluation rule, a combiner uses the cdr -- ("README") -- of the form it appears in as operand, and so it doesn't see the :mode slot.
I think it boils down to this: once we have arbitrary slots and not just car and cdr, it may make sense to remove the usual Lisp rule that the car of a combination contains its combiner. Maybe we need an explicit combiner slot:
(:combiner open-file "README" :mode "rw")
which corresponds to
(:combiner open-file :mode "rw" :car "README" :cdr ())
or abbreviated, using \ for :combiner.
(\open-file "README" :mode "rw")
Mirroring the fact that there's no nil, this also has the nice symmetry that calling a combiner without arguments requires no car and cdr anymore:
(\foo) means simply (:combiner foo), without car and cdr.
Mirroring the fact that there's no nil, this also has the nice symmetry that calling a combiner without arguments requires no car and cdr anymore:
(\foo) means simply (:combiner foo), without car and cdr.
Investigating!
Sunday, April 1, 2012
First-class patterns
A good sign: xonses are already making me think previously impossible thoughts.
In my Kernel implementation Virtua, every object can potentially act as a left-hand side pattern.
A pattern responds to the message match(lhs, rhs, env) -- where the LHS is the pattern -- performs some computation, and possibly updates env with new bindings. The rules for Kernel's built-ins are:
In my Kernel implementation Virtua, every object can potentially act as a left-hand side pattern.
A pattern responds to the message match(lhs, rhs, env) -- where the LHS is the pattern -- performs some computation, and possibly updates env with new bindings. The rules for Kernel's built-ins are:
- #ignore matches anything, and doesn't update the environment.
- Symbols match anything, and update the environment with a new binding from the symbol to the RHS.
- Nil matches only nil, and doesn't update the environment.
- Pairs match only pairs, and recursively match their car and cdr against the RHS's car and cdr, respectively.
- All other objects signal an error when used as a pattern.
With these simple rules one can write e.g. a lambda that destructures a list:
(apply (lambda (a b (c d)) (list a b c d))
(list 1 2 (list 3 4)))
==> (1 2 3 4)
(apply (lambda (a b (c d)) (list a b c d))
(list 1 2 (list 3 4)))
==> (1 2 3 4)
Now, why stop at these built-ins? Why not add first-class patterns? We only need some way to plug them into the parsing process...
An example: In Common Lisp, we use type declarations in method definitions:
(defmethod frobnicate ((a Foo) (b Bar)) ...)
(a Foo) means: match only instances of Foo, and bind them to the variable a.
Generalizing this, we could write:
(defmethod frobnicate ([<: a Foo] [<: b Bar]) ...)
The square brackets indicate first-class patterns, and in Lisp fashion, every first-class pattern has an operator, <: in this case. The parser simply calls <: with the operands list (a Foo), and this yields a first-class pattern, that performs a type check against Foo, and binds the variable a.
Another example would be an as pattern, like ML's alias patterns or Common Lisp's &whole, that lets us get a handle on a whole term, while also matching its subterms:
(lambda [as foo (a b c)] ...)
binds foo to the whole list of arguments, while binding a, b, and c to the first, second, and third element, respectively.
Another example would be destructuring of objects:
(lambda ([dest Person .name n .age a]) ...)
would be a function taking a single argument that must be an instance of Person, and binds n and a to its name and age, respectively.
With first-class patterns, all of these features can be added in luserland.
Another example would be destructuring of objects:
(lambda ([dest Person .name n .age a]) ...)
would be a function taking a single argument that must be an instance of Person, and binds n and a to its name and age, respectively.
With first-class patterns, all of these features can be added in luserland.
Xonses
I think I finally had the breakthrough regarding named parameters and conses: Xonses.
In short:
(open-file "README" :mode "rw" :create-if-not-exists #t)
===
{ :mode "rw" :create-if-not-exists #t :car "open-file" :cdr { :car "README" :cdr {} } }
A bit more here on the klisp group, and I'll keep you posted here, of course.
In short:
(open-file "README" :mode "rw" :create-if-not-exists #t)
===
{ :mode "rw" :create-if-not-exists #t :car "open-file" :cdr { :car "README" :cdr {} } }
A bit more here on the klisp group, and I'll keep you posted here, of course.
Friday, March 30, 2012
Programming and boringness
"Computers are useless. They can only give you answers." -- Picasso
"The use of a program to prove the 4-color theorem will not change mathematics - it merely demonstrates that the theorem, a challenge for a century, is probably not important to mathematics." -- PerlisOnce we can program a computer to solve a problem, that problem becomes boring.
It seems that when something is programmable, computable, it immediately loses its appeal as an endeavour for humans. Something that can be solved by an unthinking machine is no longer worthy of study by humans. (What remains to be of interest to humans are better ways to solve the same problem - write the same program better, more efficiently, more elegantly - but these seem second-order, once we have solved the problem.)
Of course this question opens a whole can of worms about what it means to be computable - e.g. does it have to be economically computable, or does it have to be computable before the end of the universe? But in general, I think that programming is interesting, because it touches upon the interesting issue of what it means to be boring.
